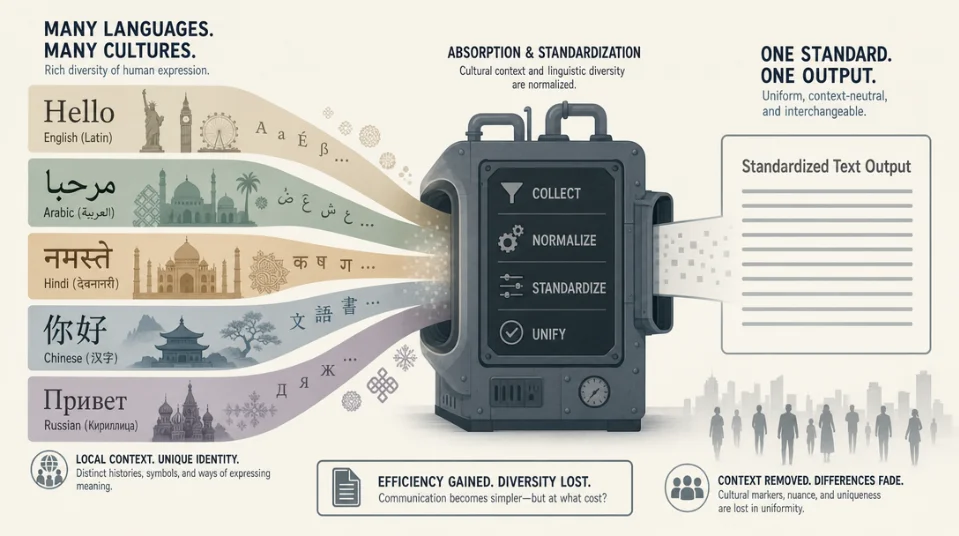
AI × 应用语言学前沿2026. 05. 27. 12:32:15语言均质化机器:LLM 预训练的语体偏见与方言的代价LLM 预训练数据里的语体偏见、写作助手对非主流英语的文化标记抗除、方言与非标准语言在 AI 系统中面临的结构性局限——三篇论文从数据、模型行为和制度批判三个层面提问:谁的语言被 AI 当成默认值?
AI × 应用语言学前沿2026. 05. 27. 12:32:01BabyLM 实验室:语言习得理论在大模型里如何接受检验?BabyLM 双语实验发现双语输入对统计学习者没有原则性障碍;小规模模型在而这个实验中把实证了构式语法的“统计先发抑制”构延“不可说”的因果来源;其中一篇坑进百个词的场景如何预测児童词汇习得难度。
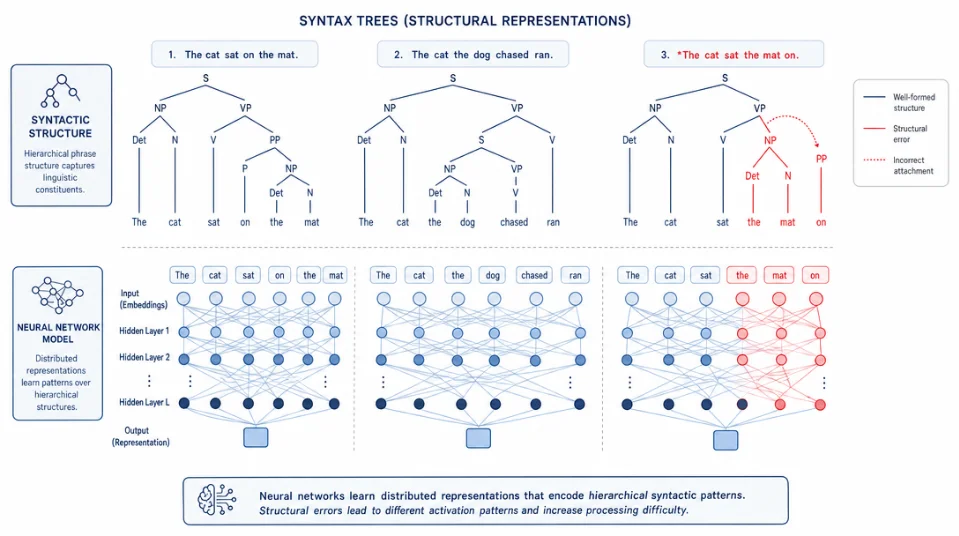
AI × 应用语言学前沿2026. 05. 27. 12:31:16大模型的语法盲区:它标注了语言,还是只是在猜?三篇实证研究从不同角度测试了 LLM 对语言形式结构的真实理解能力:句法标注错误率、大脑对齐度的训练轨迹、以及 NLP 为何始终依赖语言学——结论都指向同一道裂缝。
AI × 应用语言学前沿2026. 05. 21. 10:47:10语言学如何重返 AI:三条路径,三种立场语用评估、语言习得理论测试、语言人类学田野——近期论文和两本顶级人类学期刊专刊,展示了语言学家以三种截然不同的方式重新介入 AI 研究。