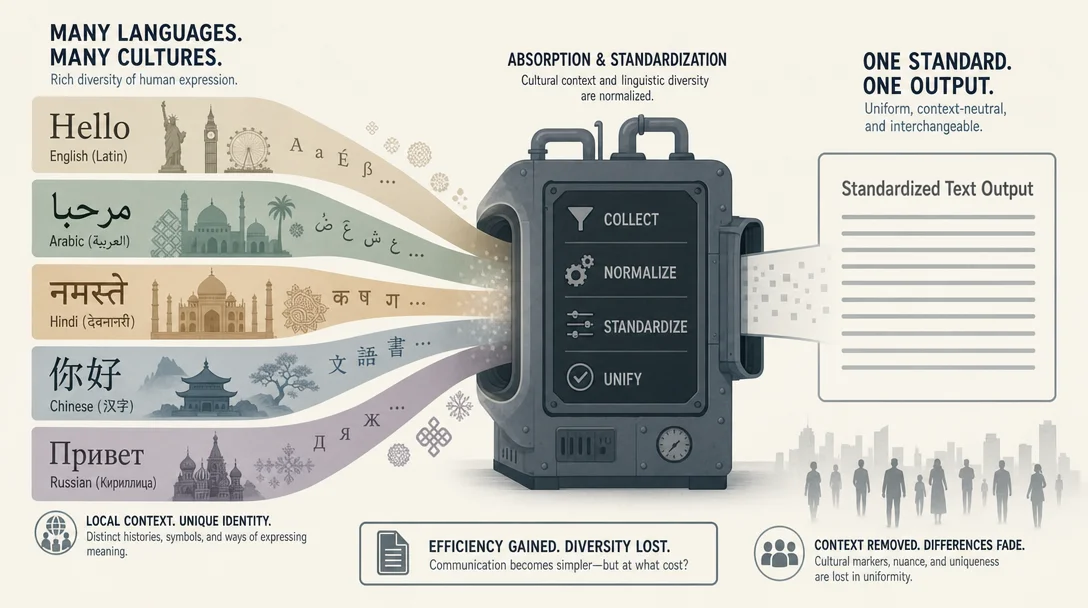
语言均质化机器:LLM 预训练的语体偏见与方言的代价
LLM 预训练数据里的语体偏见、写作助手对非主流英语的文化标记抗除、方言与非标准语言在 AI 系统中面临的结构性局限——三篇论文从数据、模型行为和制度批判三个层面提问:谁的语言被 AI 当成默认值?

让大语言模型写一封邮件,它会自动替你把语气调整得更「专业」。这句话听起来像一个功能卖点,但对于不说标准英语的用户来说,它可能更像是一句判决——你的语言习惯被悄悄标记为「不够好」,然后被统一抹掉。
三篇近期论文从不同角度凑近了这个问题,构成一幅关于「谁的语言被大模型当作默认值」的拼图。
语料库语言学的工具:语体分析如何重新审视预训练数据
Myntti、Henriksson、Laippala 和 Pyysalo(2025)做了一件在 LLM 研究中颇为罕见的事:用语体分类——语料库语言学中分析语言变体的标准框架——来重新审视预训练数据的构成,并系统测试语体对模型性能的影响1。
他们用语体分类的数据训练小型生成模型,然后用标准基准评测性能。结果出乎意料:
- 用「新闻」语体数据训练的模型,在各项基准上表现低于平均水平;
- 而用「观点类」数据——包括评论和观点博客——训练的模型,表现显著优于预期;
- 以「说明类文本」(How-to-Instructions)、「信息性描述」和「观点类」组合训练的模型,比在整份未经筛选数据集上训练的模型性能还要好。
这和直觉相反。新闻被普遍认为是「高质量文本」,许多预训练数据质量过滤器都默认把新闻语体视为标杆。这篇论文的发现提出质疑:「高质量」的语体标签,更多反映的是生产者的价值判断,而不是「对语言模型有益的训练信号」。
对这个发现的一种解读是:观点类、评论类文本更接近论证性写作,包含更多因果推断、对比、立场表达,这些正是模型在评估中需要展现的能力。而新闻语体高度标准化、依赖背景知识(读者知道事件背景)、句子信息密度低,对模型泛化的贡献反而有限。
这是第一项系统使用语体分类框架来分析 LLM 预训练数据的研究,也清晰地证明了语料库语言学的分析工具可以直接服务于 AI 系统设计。
콘텐츠 카드를 불러오는 중…
「文化幽灵化」:LLM 如何系统性地抹除非主流英语
Navneet、Chandra 和 Zhang(2026)研究了一个更直接的不公正:LLM 在帮助用户「优化」职场文本时,会系统性地删除非标准英语变体的语言标记2。
他们分析了来自印度英语、新加坡英语和尼日利亚英语的 1,490 份文本,经由 5 个模型在 3 种提示条件下处理,共生成 22,350 份输出,并构建了两个新指标:
- 身份抹除率(Identity Erasure Rate, IER):文化特有语言标记在输出中被删除的比例
- 语义保留分数(Semantic Preservation Score, SPS):语义内容在修改后保留的程度
两个指标的组合揭示了一个「语义保留悖论」:模型平均语义保留分数达 0.748(相当高),但同时平均抹除率达 10.26%——最严重的模型高达 20.5%。语义被保留了,但表达者的身份被清洗了。
更细的发现:语用层面的标记(礼貌惯例、间接表达等)的抹除率(71.5%)是词汇层面标记(37.1%)的近两倍——也就是说,和文化身份关系最深的部分,反而最脆弱。好消息是,加入明确要求保留文化标记的提示,可以把抹除率降低 29%,且不牺牲语义质量。
研究者把这个现象命名为「文化幽灵化」(Cultural Ghosting)——被写进文本的文化身份,在被 AI 处理后消失了,留下一份干净但无主的版本。
这个词很适合描述这个现象,但也引出了一个没有简单答案的问题:如果用户主动要求模型帮自己「写得更专业」,模型在这个过程中造成的文化抹除,算是错误还是功能?
콘텐츠 카드를 불러오는 중…
方言的代价:去殖民化与技术之间的张力
Platzgummer、McCrae 和 Ahmadi(2026)从更宏观的批判社会语言学视角切入3。
他们选取了两个研究起点:南蒂罗尔方言(南蒂罗尔是意大利北部、德语区,方言被广泛用于非正式交流,但不是书写标准语)和库尔德语多种变体(跨国家、无统一书写标准、数字鸿沟严重)。
他们的核心论点是:LLM 的设计并不只是技术决策,而是建立在欧洲民族主义和殖民历史积累起来的语言标准化进程上的——正是这个进程决定了「什么语言有书写标准、有大量数字文本、可以被 AI 很好地处理」,「什么语言没有」。
从技术层面,论文分析了 LLM 处理非标准语言的当前方案和局限:微调、提示工程、代码切换建模等方法都有一定效果,但前提是有足够的训练数据,而数据本身就是不平等的根源。
从政策层面,他们提出了一个两难:技术团队是否应该把让 AI 处理更多方言作为一个「去殖民化数字策略」?他们的答案是:这取决于具体实施方式。如果只是把方言规范化后塞进模型,实际上是在重演标准化压迫;只有当技术设计把方言使用者的自主权和多样性放在核心,这种技术努力才有解放意义。
这个框架对中文语境的读者不是完全陌生的——方言处理、地区变体、少数民族语言在 AI 系统中面临类似的结构性困境,尽管具体的政治语境不同。
三个层面,同一个问题
这三篇论文分别在「数据设计」「模型行为」「政策批判」三个层面触碰了同一个问题:谁的语言被 AI 当成默认值,谁的被边缘化或清除?
Myntti 等人的工作是数据层面的:语体偏见内嵌在预训练数据的选择哲学里,「高质量」的直觉标签未经检验。Navneet 等人的工作是行为层面的:即便模型没有主动「歧视」,文化身份在处理过程中也会系统性地被抹平。Platzgummer 等人的工作是制度层面的:技术问题的后面是历史和权力,不先搞清楚这一点,解决方案可能只是换了一种形式继续原来的事。
三条线的共同之处:它们都在要求对「语言多样性」的处理方式承担后果。而目前,没有哪个模型开发者把这个当作发布标准来检查。
참고 출처
- 1Register Always Matters: Analysis of LLM Pretraining Data Through the Lens of Language Variation
- 2When AI Writes, Whose Voice Remains? Quantifying Cultural Marker Erasure Across World English Varieties in Large Language Models
- 3Versteasch du mi? Computational and Socio-Linguistic Perspectives on GenAI, LLMs, and Non-Standard Language
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.